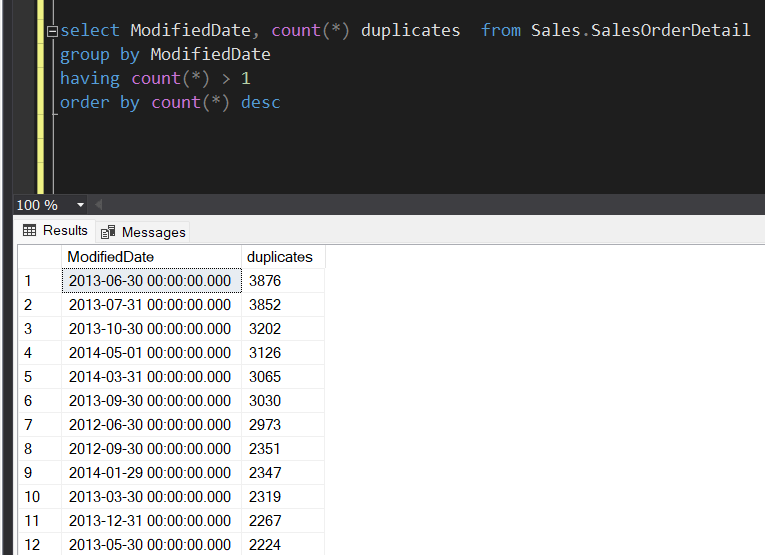
In a single column:
To get duplicates on a specific column, you can use the GROUP BY and COUNT(*) statements. For example, to find duplicates on the “ModifiedDate” column of the “Sales.SalesOrderDetails” table from the “AdventureWorks” sample database, you can use the following code:
SELECT ModifiedDate, COUNT(*) duplicates
FROM Sales.SalesOrderDetail
GROUP BY ModifiedDate
HAVING COUNT(*) > 1
ORDER BY COUNT(*) descResult:
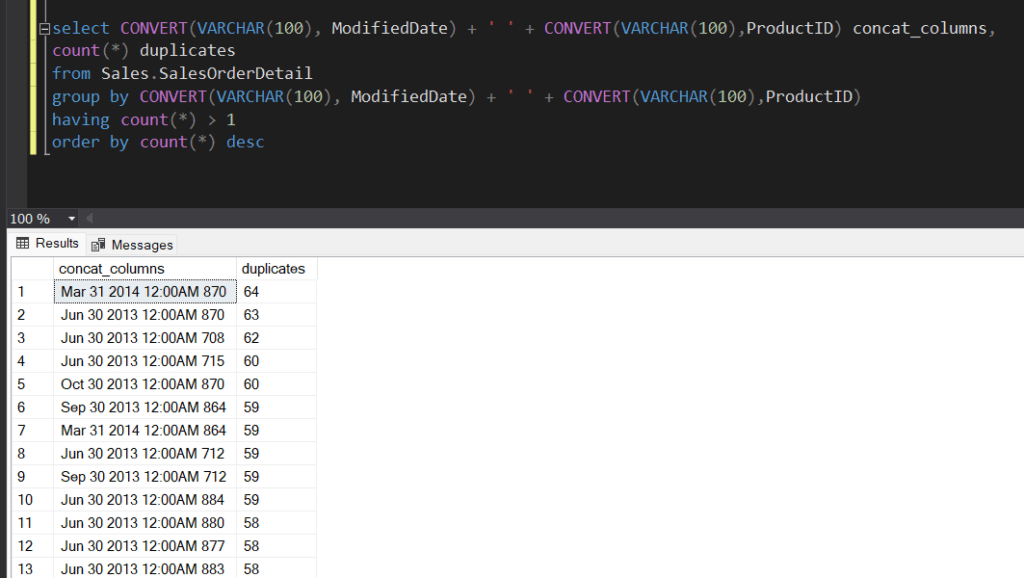
In multiple columns:
Similarly, GROUP BY and COUNT(*) can be used too, but, in this case, we could convert each column to VARCHAR (so that they have all the same data type) and then concatenating them. For example, let’s use the “ModifiedDate” and “ProductID” fields from the same table:
select CONVERT(VARCHAR(100), ModifiedDate) + ' ' + CONVERT(VARCHAR(100),ProductID) columns,
count(*) duplicates
from Sales.SalesOrderDetail
group by CONVERT(VARCHAR(100), ModifiedDate) + ' ' + CONVERT(VARCHAR(100),ProductID)
having count(*) > 1
order by count(*) descResult: